- Blog /
- VictoriaLogs Status Update: Heading Towards the Cluster Version

VictoriaLogs Status Update: Heading Towards the Cluster Version
Share:



Today, we’re thrilled to share the latest updates on VictoriaLogs, your trusted open-source solution for efficient and user-friendly log management. Whether you’re just discovering VictoriaLogs or have been using it for a while, this post will walk you through the recent enhancements and give you a sneak peek at the much anticipated cluster version that’s on the horizon.
Since its first release, and walking in VictoriaMetrics’ footsteps, VictoriaLogs has been about delivering top-notch performance without the hefty resource demands. It uses up to 30 times less RAM and up to 15 times less disk space compared to alternatives like Elasticsearch and Grafana Loki. This efficiency means VictoriaLogs can run smoothly on anything from a Raspberry Pi to high-end servers with hundreds of CPU cores and terabytes of RAM.
Why Choose VictoriaLogs?
#
One of the standout features of VictoriaLogs is its simplicity. Setting it up is a breeze, with minimal configuration required. This means you can dive right into managing your logs without getting bogged down by complex tuning processes. Plus, VictoriaLogs integrates seamlessly with popular log collectors, making it a perfect fit for your existing setup.
For those who need robust querying capabilities, VictoriaLogs offers LogsQL—a query language that’s both user-friendly and powerful. With full-text search capabilities across all log fields, LogsQL makes it easy to extract meaningful insights from your logs. The built-in web UI and Grafana plugin further enhance your ability to explore and visualize logs, while the interactive command-line tool adds an extra layer of flexibility.
VictoriaLogs is built to handle logs with high cardinality fields, such as trace IDs, user IDs, and IP addresses, making it ideal for complex log analysis. It also supports wide events, which are logs with hundreds of fields, and provides multitenancy support for managing multiple users or projects within a single instance.
Technical Insights
#
VictoriaLogs sets itself apart from competitors like Elasticsearch and Grafana Loki by utilizing bloom filters by default instead of inverted indexes. Bloom filters are efficient data structures that quickly determine whether a specific term, like “error,” exists within a block of logs. This allows VictoriaLogs to skip irrelevant blocks, saving both time and resources, especially when searching for rare terms within logs.
Efficiency and Cost Savings
#
By leveraging bloom filters, VictoriaLogs significantly reduces disk I/O and CPU usage, avoiding unnecessary data processing. This results in substantial cost savings, particularly when dealing with large volumes of logs. Unlike other solutions that may struggle with high cardinality fields like IP addresses or trace IDs, VictoriaLogs handles these efficiently, ensuring optimal performance.
Log Streams and Indexing
#
VictoriaLogs employs the concept of log streams, popularized by Grafana Loki. Log streams group logs from a single source, making it easier to explore logs from specific applications. VictoriaLogs improves upon this by not requiring users to configure indexes, which can be complex and time-consuming in systems like Elasticsearch. This simplicity allows VictoriaLogs to work efficiently out of the box, automatically indexing all log fields received.
Query Language and Performance
#
The query language in VictoriaLogs, LogsQL, is designed for simplicity and power. Users can perform straightforward searches or complex queries with ease. The system supports data extraction functions and analytical calculations, optimized for speed and performance. Inspired by ClickHouse, VictoriaLogs uses techniques that ensure fast query processing, even over large datasets. We’d go so far as to say that LogsQL is better than SQL in pretty much all aspects: It is easier to write, it is easier to read and follow, and it is more powerful: See our docs for details.
Parallel Processing
#
VictoriaLogs parallelizes the execution of heavy queries on all available CPU cores. This means that when a query is executed over a large volume of logs, the system reads and processes these logs in parallel, significantly reducing query duration. This capability allows VictoriaLogs to scale vertically on a single node, making it highly efficient for large-scale log analysis.
Advanced Functionalities and Use Cases
#
VictoriaLogs offers a robust platform for tracking and analyzing logs, providing powerful functionalities that cater to a wide range of use cases. For instance, if you’re interested in tracking new GitHub issues that mention a specific word, such as “DeepSeek,” the VictoriaLogs playground has you covered. You can explore issues opened on a specific date using a simple query interface.
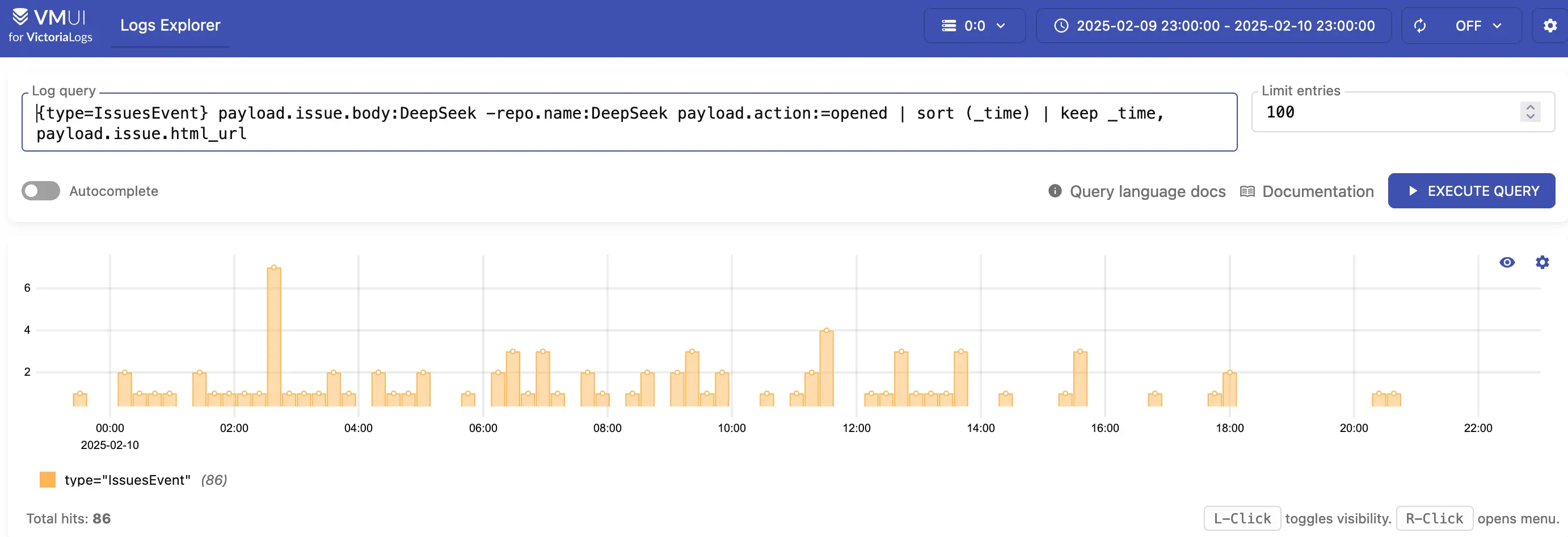
Moreover, if you’re curious about which GitHub issues have garnered the most comments, VictoriaLogs allows you to delve into this data effortlessly. The platform’s intuitive query capabilities make it easy to identify trends and insights within large datasets.
More recently, VictoriaLogs introduced such useful functions like the histogram stats function for heatmap visualizations in Grafana and the union pipe for combining results from multiple queries. These enhancements further solidify VictoriaLogs as a versatile tool for log analysis.
For those dealing with large-scale log data, VictoriaLogs provides tools like the collapse_nums pipe to analyze and identify patterns, such as determining which sources contribute the most to your log volume. This is particularly useful for managing and understanding “big data” environments, where a single node can process vast amounts of data efficiently.
VictoriaLogs also supports alerting functionalities, allowing users to set up notifications based on log data, ensuring that critical issues are addressed promptly. Additionally, with support for joins, users can perform complex queries that combine data from multiple sources, enhancing the platform’s analytical capabilities.
Recently, VictoriaLogs demonstrated its ability to efficiently ingest and query wide events—logs with hundreds of high-cardinality fields. By successfully handling events from the GitHub Archive, VictoriaLogs showcased its capacity to manage and analyze complex datasets at high speeds.
Upcoming Cluster Version of VictoriaLogs
#
We are excited to announce updates regarding the upcoming cluster version of VictoriaLogs:
- Seamless Migration: The migration from single-node VictoriaLogs to the cluster version will be seamless. Users can replace the single-node executable with the storage node executable, as both versions share an identical data storage format. This allows users to start with the single-node version and instantly switch to the VictoriaLogs cluster when it becomes available.
- Global Querying: The “select” component of the VictoriaLogs cluster will provide a global querying view across multiple single-node instances. Users can start collecting different logs into multiple single-node instances and explore all these logs via a single query once the cluster version of VictoriaLogs is published.
VictoriaLogs Status Update: We’re Just Getting Started!
#
VictoriaLogs represents a significant advancement in observability, combining efficiency, simplicity, and performance. As we continue to innovate, our focus remains on providing users with the tools they need to manage and analyze their data effectively. With its ability to handle high cardinality fields, efficient query processing, and support for wide events and traces, VictoriaLogs is set to become an indispensable tool for engineers, developers and enterprises alike.
Stay tuned for more updates and get started with VictoriaLogs here!
Leave a comment below or Contact Us if you have any questions!
comments powered by Disqus