- Blog /
- Performance optimization techniques in time series databases: Limiting concurrency

Performance optimization techniques in time series databases: Limiting concurrency
Share:



This blog post is also available as a recorded talk with slides.
Table of Contents
Performance optimization techniques in time series databases:
- Strings interning;
- Function caching;
- Limiting concurrency for CPU-bound load (you are here).
- sync.Pool for CPU-bound operations.
Monitoring is about reflecting services state in time. The services we monitor, in most cases, exist for a significant amount of time, and we collect their metrics at fixed intervals. Thanks to this, the ingestion rate (writes) to a time series database can be stable and predictable.
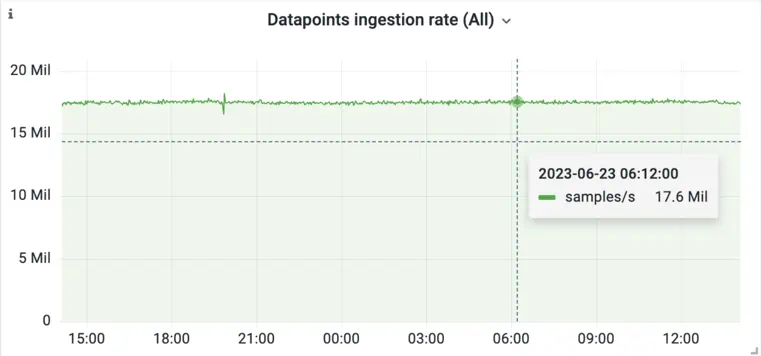 An example of stable ingestion rate of metrics samples in VictoriaMetrics database.
An example of stable ingestion rate of metrics samples in VictoriaMetrics database.
But with Kubernetes many services run in auto-scaling mode, when the number of their replicas can change depending on demand. So does the number of targets that vmagent or VictoriaMetrics Single Server needs to scrape generating fluctuations in the ingestion pattern.
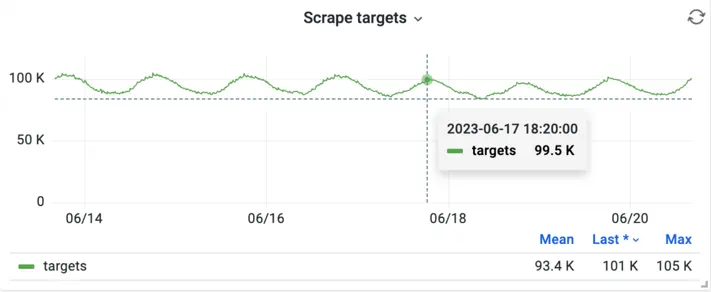 Daily fluctuations in the number of scrape targets for an application.
Daily fluctuations in the number of scrape targets for an application.
Alongside more predictable fluctuations, sometimes a times series database needs to be able to cope with huge spikes in ingestion load. Examples include if someone deploys a new application with new metric names, or if there’s a bug that generates a large number of incorrect metric names.
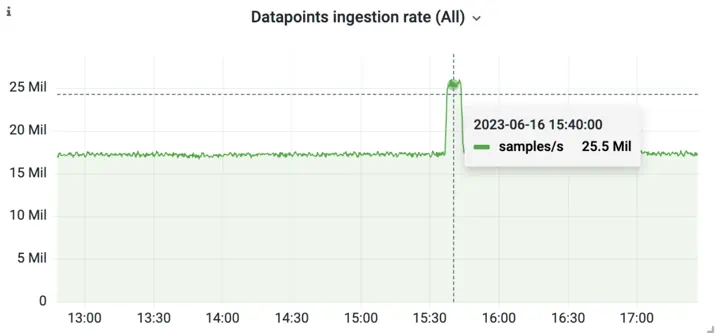 An example spike in the ingestion rate for an application.
An example spike in the ingestion rate for an application.
When spikes occur, we need to make sure that increase in workload doesn’t crash the database. Spikes often coincide with the times that you need your monitoring the most. Rollouts of new applications and diagnosing bugs both benefit from reliable monitoring.
One technique VictoriaMetrics uses to ensure reliability in these cases is to limit concurrency. Limiting concurrency brings benefits for both CPU and memory usage:
- CPU - The machine(s) running VictoriaMetrics only have a finite number of cores. By limiting concurrency, you reduce contention between threads and context switching. Context switching between threads is expensive, and when spikes occur, you want your CPUs to work as efficiently as possible.
- Memory - Each running thread adds to the memory overhead of your application. By reducing the number of concurrent threads, you reduce the memory usage.
That said, limiting concurrency is not without its downsides. The biggest issue is that it introduces complexity to your application which could lead to accidental deadlocks or inefficient resource utilization.
For example, a thread could be waiting on I/O from storage or the network. I/O is unpredictable and often comes with large delays. By limiting the number of threads that can run concurrently, you increase the risk of under-utilizing the CPU while waiting on I/O. This is why it’s important to only limit concurrency for CPU-intensive workloads that doesn’t depend on I/O.
There are multiple ways of implementing limited concurrency. Below are two examples.
Worker pool implementation
#
The canonical way to limit the amount of concurrency in your application is to spawn a limited number of worker threads and share a channel between them for dispatching work. The code might look something like the below:
// Limit concurrency with number of available CPUs
var concurrencyLimit = runtime.NumCPU()
func main() {
workCh := make(chan work, concurrencyLimit)
for i := 0; i < concurrencyLimit; i++ {
go func() {
for {
processData(<-workCh)
}
}()
}
putWorkToCh(workCh)
}
The code above first finds out the number of CPUs the machine has using Go’s runtime library.
It then spawns a number of worker threads equal to the number of CPUs, and each runs the processData function.
It also creates a shared channel to distribute work among them, workCh.
This approach works well but comes with a few downsides:
- Complicated implementation - This approach requires implementing start and stop procedures for workers.
- Additional synchronization - If the units of work are small, then the overhead of distributing work through a channel is relatively large.
This approach provides a good solution for limited concurrency, and might work well for your application. That said, it’s worth comparing it to a token-based implementation as described below.
Token-based implementation
#
An alternative approach is to implement a gate that workers need to pass before they can run. One implementation of this approach is to create a channel with a limited buffer size and make workers attempt to put a dummy value into that channel, a token, before running. Workers will then take a dummy value from the channel once they are finished. Since the channel has a limited buffer size, only a limited number of workers can run at once. Take a look at the code snippet below:
var concurrencyLimitCh = make(chan struct{}, runtime.NumCPU())
// This function is CPU-bound and may allocate a lot of memory.
// We limit the number of concurrent calls to limit memory
// usage under high load without sacrificing the performance.
func processData(src, dst []byte) error {
concurrencyLimitCh <- struct{}{}
defer func() {
<-concurrencyLimitCh
}()
// heavy processing...
The code above creates a channel called concurrencyLimitCh that has as many slots as there are CPUs on the machine.
The processData function does some CPU-heavy processing, and so before running, it requests a token from
concurrencyLimitCh by placing a dummy value in the channel. It might be easier to visualize what’s happening
as a series of steps:
processDataattempts to place an empty struct inconcurrencyLimitCh. This acts as its permission token and will block until a slot becomes available.processDatadoes its CPU-intensive work.processDatadefers taking an item fromconcurrencyLimitChuntil after it has finished its work. Taking an item from the channel frees up a slot, and lets another worker run.
This approach guarantees that no more than len(concurrencyLimitCh) workers are running at the same time,
since each worker has to secure a slot before it does any intensive work.
This is much simpler than running separate workers, because you don’t need start and stop routines for each worker.
Your application can spawn a worker goroutine whenever a unit of work comes in and concurrencyLimitCh does
the hard work of guaranteeing that no more than some maximum number of workers are running at once.
Summary
#
Limiting concurrency can help to bound resource usage and protect your application from crashing during load spikes. It ensures that your application processes load without interruptions in an optimal manner instead of wasting resources on context switches.
This approach works best for CPU-bound operations, and doesn’t apply as well to I/O-bound operations since they involve waiting on external resources.
Stay tuned for the new blog post in this series!
Leave a comment below or Contact Us if you have any questions!
comments powered by Disqus