- Blog /
- How to Choose a Scalable Open Source Time Series Database: The Cost of Scale

How to Choose a Scalable Open Source Time Series Database: The Cost of Scale
Share:



When looking for a highly scalable time series database, there are a number of criteria to investigate and evaluate.
First up, it’s always a good idea to consider open source software. It’s more likely to have gone through comprehensive troubleshooting, it’s typically more reliable as it has more timely and widespread peer-review, it better guarantees technology independence, it’s easier to find engineers who are familiar with it and it has great security. Organizations can use open source software for as long as they want including in the form of their choice.
So now you’ve decided on an open source time series database, what are the key criteria to look at to further refine your search?
- Multi-tenancy
- Horizontal and vertical scalability
- High availability
- Cost effectiveness
It’s also important to look at the following time series-specific functionalities and whether they are supported by the solution you’re evaluating:
- Thorough and honest documentation that states exactly what happens in reality
- Integrations with popular ingestion protocols (such as Prometheus or Graphite)
- Ability to visualize time series (integration with Grafana or own UI)
- Alerting support
- Downsampling of historical data for more efficient storage
Architecture
#
From an architectural perspective, it is recommended that the following concepts and questions be considered (this is a non-exhaustive list but what we recommend based on our experience):
- Is object storage the best option?
- Is a local file system preferable, especially if you’re looking for query speed performance?
- Can the solution you’re evaluating be used as a single binary, in cluster mode, or both?
- How many “moving parts” does it contain?
Open Source & Licensing
#
We always recommend open source over proprietary or otherwise not fully open technology. It’s important to look not only at a solutions’ code and features but also how its licensing is structured.
- Is the solution based on original code?
- What type of license does it come with?
- Is it an Apache 2 license for example?
- Or, is it an AGPLv3 license, which implies restrictions on use?
There are many other licenses in the market and AGPLv3 is not the worst. It allows using software for commercial purposes, but requires open sourcing any modifications made to it. This license does not affect small companies or startups, but protects against building a business based on it, because it usually requires some code changes for better integrations.
These are important questions to investigate and find answers for up front so that you don’t find yourself locked-in or restricted by licensing requirements that you hadn’t anticipated.
The cost of scale
#
In terms of measurement when it comes to choosing a most scalable time series database it’s important to do due diligence and fully test for key indicators such as:
- Bottlenecks in query or ingestion performance
- Scaling factor
- The best characteristic is linear scaling which means if you double resources then the capability of the system is also doubled.
- Unfortunately, this is rare in distributed systems. Most of the systems have a coefficient of the scaling, which means if you double resources you get only only 30% of additional capability.
- The best characteristic is linear scaling which means if you double resources then the capability of the system is also doubled.
- Compression efficiency
- Resource usage
Resource usage can be a determining factor both from a system as well as from a budgetary perspective.
As some of you will know from experience: great scale can quickly lead to great cost!
So some of the questions to always ask are:
- What is the cost of the scale?
And
- What do the unit economics look like?
Knowing the answers to these questions will help you to make not just the most relevant technical decision, but also the most cost-effective one.
More on our thoughts with regards to cost (of scale) and cost in general is documented in this blog post.
Object Storage vs Local File System
#
While object storage in the cloud is the new approach and file system is the traditional one, object storage became an option only recently, with the rise of AWS which can make it quite cheap.
However, there are pros and cons to both.
Some object storage pros:
- It is infinite
- You pay only for what you use, no need to resize the storage
- It is durable, as cloud providers promise
- It is cheap for storing data
- Actually, it could be more expensive than local storage in some scenarios, but in general, for storing time series data it is usually cheaper. Slower but cheaper.
Some object storage cons:
- It has significantly higher latency than a local filesystem
- The network bandwidth could become a bottleneck
Some local file system pros:
- Provides the best options for really good read performance
- Does super-fast, almost instant, backups
- This is only possible on local filesystems, because they support “hard links”, so no data copying is done
- Allows for mutating (merging) of data aggressively to achieve better compression on disk
- No hidden costs on storage
Some local file system cons:
- It has a higher price per GB
- It has limited size and requires resizing when needed
- It requires additional availability guarantees - cloud providers usually do provide these guarantees (Google’s regional persistent disks). But when running it on premises - one should take care of it.
So what is probably the most scalable open source time series database?
#
This blog post isn’t entirely innocent of course, and we do have a take on the question.
With VictoriaMetrics we focus on performance, simplicity and reliability, which allows us to achieve both high scalability and availability. We believe that the local file system set up provides the best options for outstanding read and write performance.
We also always make sure that VictoriaMetrics has few moving components and no extra dependencies in order to make it as easy to operate as possible.
This was one of the key reasons why VictoriaMetrics was developed in the first place: to remove the complexity that exists in other solutions to make monitoring as accessible as possible to everyone who needs it.
What makes VictoriaMetrics particularly scalable and available?
#
- Each service may scale independently
- Each service may run on hardware optimized for the service needs
- Heavy inserts don’t interfere with heavy selects
- Better vmstorage durability because it offloads complex querying logic to vmselect
- Built-in replication
- Per-tenant rate-limiting
VictoriaMetrics’ cluster version is a great option for ingestion rates over a million data points per second and this is what its architecture looks like:
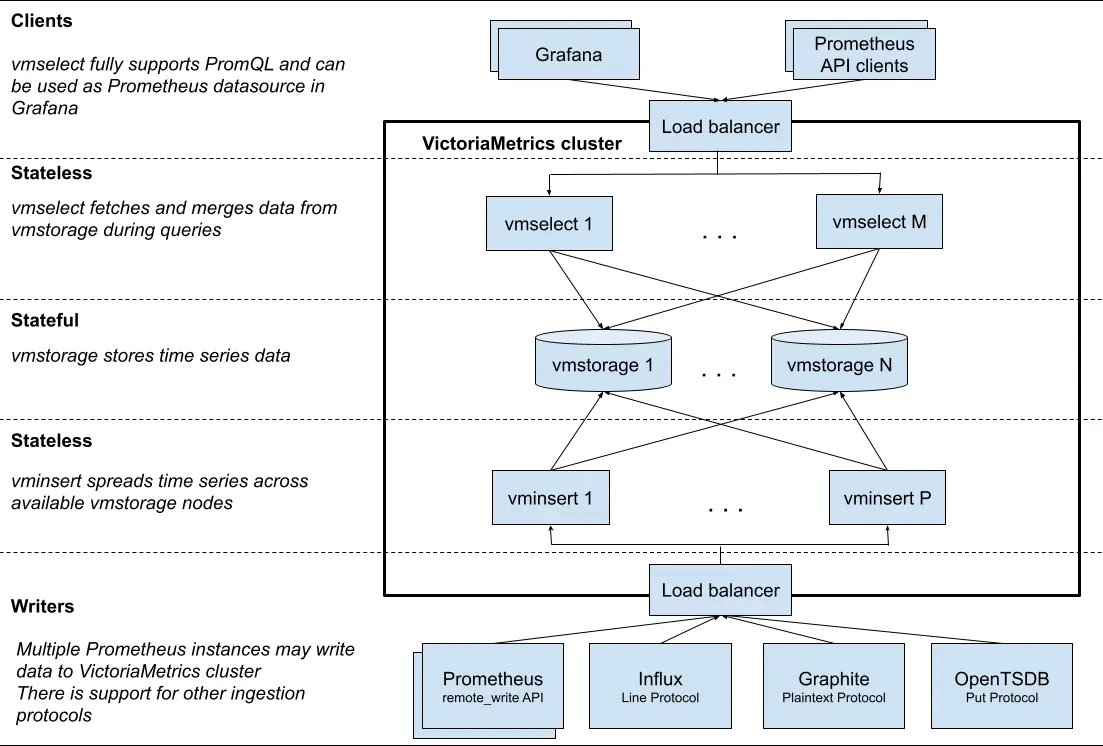
Cluster performance and capacity can be scaled up in two ways:
- By adding more resources (CPU, RAM, disk IO, disk space, network bandwidth) to existing nodes in the cluster (aka vertical scalability).
- By adding more nodes to the cluster (aka horizontal scalability).
General recommendations for cluster scalability:
- Adding more CPU and RAM to existing vmselect nodes improves the performance for heavy queries, which process a big number of time series with a big number of raw samples.
- Adding more vmstorage nodes increases the number of active time series the cluster can handle. This also increases query performance over time series with high churn rate. The cluster stability is also improved with the number of vmstorage nodes, since active vmstorage nodes need to handle lower additional workload when some of vmstorage nodes become unavailable.
- Adding more CPU and RAM to existing vmstorage nodes increases the number of active time series the cluster can handle. It is preferred to add more vmstorage nodes over adding more CPU and RAM to existing vmstorage nodes, since higher number of vmstorage nodes increases cluster stability and improves query performance over time series with high churn rate.
- Adding more vminsert nodes increases the maximum possible data ingestion speed, since the ingested data may be split among a bigger number of vminsert nodes.
- Adding more vmselect nodes increases the maximum possible queries rate, since the incoming concurrent requests may be split among a bigger number of vmselect nodes.
The Cost of VictoriaMetrics Scale
#
The key to (cost-)efficiency is simplicity and transparency.
The less magic happens under the hood and the lower number of components is used, the better efficiency will be.
It’s not only about efficient usage of hardware resources, but also about the amount of effort engineers need to make in order to understand and maintain the software. Which, sometimes, costs a lot more than hardware.
VictoriaMetrics documentation contains clear tips for the scaling of cluster components. The Capacity planning section also contains general recommendations and performance expectations based on the amount of provided resources and workload volume.
We always pay extra attention to performance reports from our users and do everything we can to make VictoriaMetrics even better. All the performance improvements we publish are based on real-world scenarios, which we learn from and optimize together with our users.
Finally, we’re always very keen to collaborate, learn from our customers and users, their setups and specific cases.
That is, probably, the main reason why VictoriaMetrics remains on the high level of (cost-)efficiency and scalability.
Please do contact us if you’d like to discuss your own monitoring set up with us!
Leave a comment below or Contact Us if you have any questions!
comments powered by Disqus