- Blog /
- Go I/O Closer, Seeker, WriterTo, and ReaderFrom
Go I/O Closer, Seeker, WriterTo, and ReaderFrom
Share:



This article is the 2nd article in the I/O series:
- Go I/O Readers, Writers, and Data in Motion.
- Go I/O Closer, Seeker, WriterTo, and ReaderFrom (We’re here).
So, we’ve already covered readers and writers in basic, and even touched on some standard library implementations that make our lives easier things like bufio.Reader/Writer and os.File.
Still, we haven’t really covered some other important interfaces, like Closer, Seeker, and a few others. And honestly, if you’re learning Go, you probably don’t want to leave those in the blind spot. After all, the io package comes with over 20 interfaces, and while most of them are just combos of the basics (like io.ReadWriter, io.ReadWriteCloser, and so on), they’re still worth a closer look.
type ReadWriter interface {
Reader
Writer
}
type ReadWriteCloser interface {
Reader
Writer
Closer
}
In this piece, we’re going to break down most of these interfaces, though we’ll skip the ones that are just combinations of others.
1. io.Closer
#
The Closer interface is all about handling objects that need to clean up after themselves, specifically, releasing resources when you’re done with them.
type Closer interface {
Close() error
}
Most of the time, you won’t see Closer hanging out on its own.
In the Go standard library, it usually comes bundled with other interfaces, like io.ReadCloser, io.WriteCloser, or io.ReadWriteCloser. For example, when you’re done working with a file, a network connection, or maybe a database, you call the Close() method to tidy things up and free the resources.
Now, what happens when you call Close() more than once?
Take os.File, for instance, it’ll throw an os.ErrClosed error if you try closing it again. On the other hand, Response.Body from the net/http package probably won’t complain at all.
“What if I forget to close a file? Will it leak memory?”
Well, kind of… but not exactly.
When you open a file, the operating system allocates something called a file descriptor. If you don’t close that file properly, the file descriptor sticks around, and if you keep opening files without closing them, the system can eventually run out of available file descriptors. When that happens, you’ll run into errors like “too many open files.”
But don’t worry, Go has your back.
If you forget to close a file, there’s a chance Go’s garbage collector will step in and clean up the file descriptor for you when the file object is no longer in use.
Here’s a peek at how it works behind the scenes:
func newFile(fd int, name string, kind newFileKind, nonBlocking bool) *File {
f := &File{&file{
pfd: poll.FD{
Sysfd: fd,
IsStream: true,
ZeroReadIsEOF: true,
},
name: name,
stdoutOrErr: fd == 1 || fd == 2,
}}
...
runtime.SetFinalizer(f.file, (*file).close)
return f
}
See that runtime.SetFinalizer(f.file, (*file).close) line?
Go basically registers the (*file).close function to be called when the file is no longer referenced. So, when the garbage collector runs, it’ll close the file for you. But the thing is, garbage collection doesn’t happen instantly. If you leave a lot of files unclosed, they can stack up before GC gets around to it.
But hey, this is more of an internal detail, don’t rely on it. You might actually want to unlearn this little information (too late).
2. io.Seeker
#
When you open a file, or really any resource like a buffer or network stream, the default behavior is to read or write data sequentially, starting from the beginning and moving forward. But sometimes, you need a little more control, maybe you want to skip ahead to a specific spot in the file or go back and re-read something.
This is exactly what the io.Seeker interface is designed for.
type Seeker interface {
Seek(offset int64, whence int) (int64, error)
}
The Seeker lets you move the file pointer to a different position in the file.
So you can start reading or writing from that exact location. Its function takes two arguments: offset, which specifies how far you want to move the cursor, and whence, which is the reference point that determines where to start counting from:
os.SeekStart: This moves the cursor relative to the beginning of the file. So, callingSeek(0, SeekStart)takes you back to the very start of the file whileSeek(100, SeekStart)moves the cursor 100 bytes from the start.os.SeekCurrent: This moves the cursor relative to where it is right now. If you call Seek(-10, SeekCurrent), and you’ll go 10 bytes backward.os.SeekEnd: Moves the cursor relative to the end of the file, mostly you would pass negative offset.
Let’s see an example:
func main() {
reader := strings.NewReader("Hello, World!")
reader.Seek(7, io.SeekStart)
readBytes(reader)
// Output: Read 6 bytes: "World!"
reader.Seek(-5, io.SeekCurrent)
readBytes(reader)
// Output: Read 5 bytes: "orld!"
reader.Seek(-2, io.SeekEnd)
readBytes(reader)
// Output: Read 2 bytes: "d!"
}
// Helper
func readBytes(reader io.Reader) {
buffer := make([]byte, 1024)
n, _ := reader.Read(buffer)
fmt.Printf("Read %d bytes: %q\n", n, buffer[:n])
}
In this example, after seeking 7 bytes forward from the start, the readBytes function reads the string “World!” and moves the pointer to the end of the file.
One thing to keep in mind, if you open a file with the O_APPEND flag (append mode), Seek behavior is kind of undefined. This is because when a file is opened with O_APPEND, the file pointer is automatically moved to the end before every write operation, so things might not behave how you expect.
3. io.WriterTo
#
Usually, when working with files or streams, you handle data the old-fashioned way: calling Read() on the source, Write() on the destination, and transferring data chunk by chunk. But sometimes, that approach feels inefficient—after all, you’re moving data back and forth in multiple steps.
So, how can io.WriterTo help streamline that?
type WriterTo interface {
WriteTo(w Writer) (n int64, err error)
}
The WriteTo(w Writer) method is called on the source object and directly writes its data to the destination w. In most cases, WriterTo pairs nicely with io.Reader, so that the reader can now take control and write everything it has to the destination in one shot.
This streamlines the whole process.
If you want to make data transfer more efficient or customize it a bit, consider implementing these interfaces. They’ll take priority over the usual Read() and Write() calls, which means they give you a bit more control and potentially better performance.
Let’s break down what ’take priority’ actually means in practice by looking at how io.Copy() does its thing:
- WriterTo: If the source (the reader) implements the
WriterTointerface, it means the source knows how to write its data directly to the destination. So,io.Copy()calls theWriteTo()method, skipping the need for any extra buffer. - ReaderFrom: If the destination (the writer) implements
io.ReaderFrom, then it knows how to read data directly from the source, soio.Copy()calls theReadFrom()method instead. - 32 KB Buffer Fallback: If neither of those is implemented, then
io.Copy()will fall back on the usual method: reading data from the source into an internal buffer and writing it to the destination. As you may recall from the previous article, the default buffer size is 32 KB.
One more thing, these interfaces are also prioritized by bufio.Reader and bufio.Writer, which means those buffered readers and writers will look for WriterTo and ReaderFrom implementations and use them if they’re available.
“Wait, is there a better way than copying in 32 KB chunks? I mean that behavior of io.Copy() is already good, right?”
Ah, that’s something a lot of people wonder about.
Take os.File for example, it implements the WriterTo interface. So if you’re copying data from a file, os.File can go straight into action and write its content directly to another writer without going through those default 32 KB chunks.
func main() {
f, _ := os.Open("source.txt")
defer f.Close()
destFile, _ := os.Create("destination.txt")
defer destFile.Close()
n, _ := f.WriteTo(destFile)
fmt.Printf("Wrote %d bytes\n", n)
}
Here, instead of going through a manual read/write loop, we just call WriteTo() and it handles everything in one step.
But why is this faster than the fallback of io.Copy()?
Let’s say you’re reading data from a file and sending it over a network socket. Normally, data would have to be read from disk into user space (your app’s memory) and then sent back into kernel space (the network socket) and that’s a lot of back-and-forth.
Fortunately, if you’re on Linux, there’s a system call that can bypass user space entirely, transferring data directly from one file descriptor (like a file) to another (e.g., a network socket).
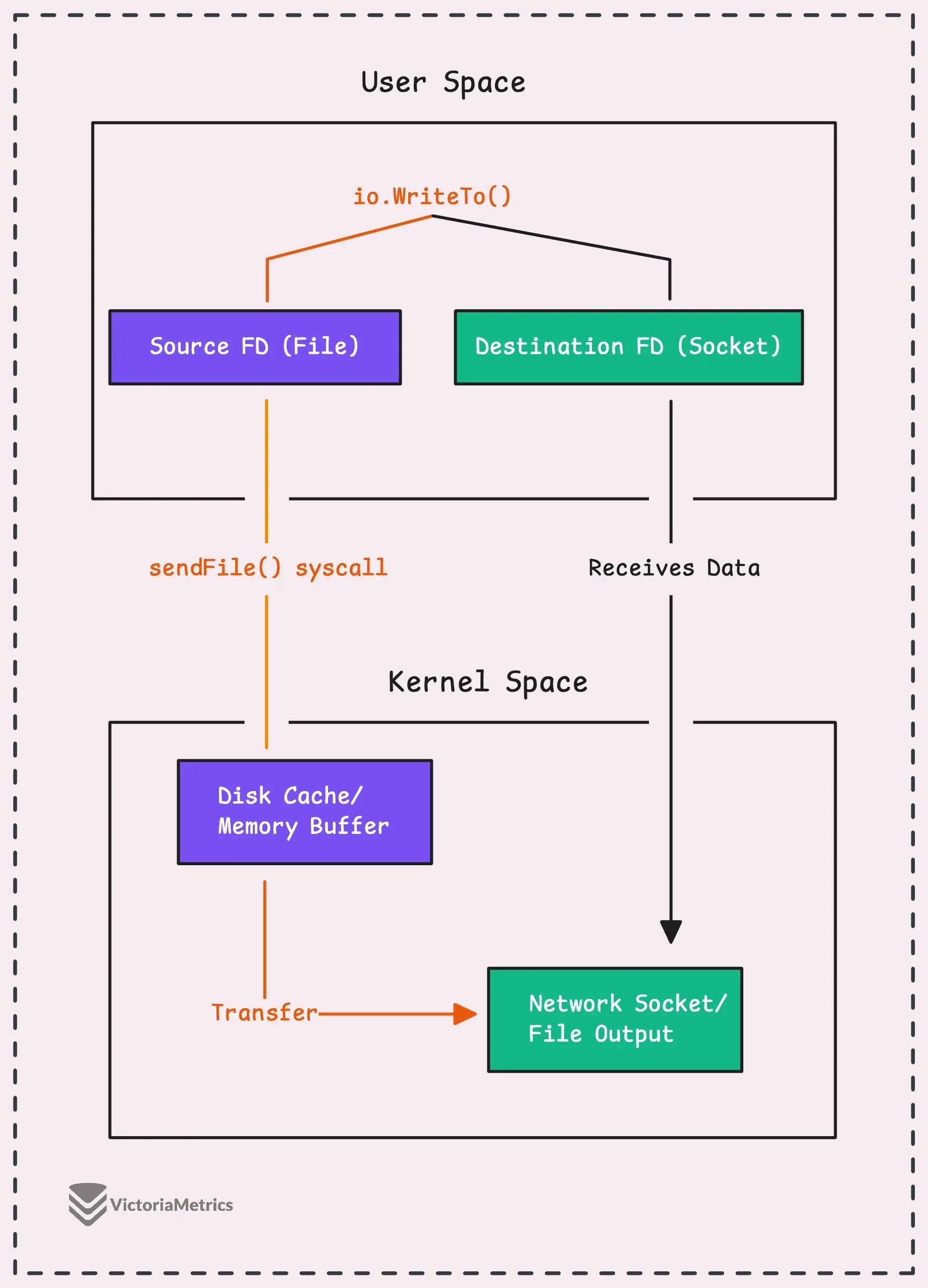
This is way more efficient because it avoids copying data between user space and kernel space altogether.
If you’re on a different platform or this direct file descriptor transfer isn’t possible, io.Copy() will handle things with the usual process, reading and writing data in 32 KB chunks.
Here’s another example: bytes.Buffer. Since it gives you direct access to its internal buffer, you already know how big the data is, and it’s all sitting in memory. Using io.Copy() here would just create an extra buffer and copy the data chunk by chunk, which is redundant. Instead, bytes.Buffer can write its entire content directly to another io.Writer in a single step.
4. io.ReaderFrom
#
The io.ReaderFrom interface is mainly implemented by types that are also io.Writer, and it’s designed to make reading data from a source (like a reader) into its object more efficient.
type ReaderFrom interface {
ReadFrom(r Reader) (n int64, err error)
}
A good example of this is os.File, which supports the ReadFrom() method to read data directly from any reader into the file:
func main() {
f, _ := os.Create("destination.txt")
defer f.Close()
r := strings.NewReader("This is some data to be read")
n, _ := f.ReadFrom(r)
fmt.Printf("Read %d bytes\n", n)
}
Just like with WriterTo, if your OS supports a more efficient way to move the data, ReadFrom() will use it. If not, it’ll fall back to the standard io.Copy() method, chunking through the data 32 KB at a time.
5. io.ByteReader/Writer & io.RuneReader/Writer
#
The ByteReader/Writer and RuneReader/Writer interfaces might seem small, but they’re really handy when you need to work with data one byte or one character at a time in Go.
Usually, when you’re writing data in Go, you’d use the io.Writer interface, which expects a slice of bytes (Write([]byte)).
But if you only need to deal with one byte at a time, that’s a bit overkill, right?
That’s where ByteWriter steps in, designed specifically for writing a single byte at a time. Similarly, io.ByteReader is all about reading one byte at a time.
func main() {
data := `{"name": "VictoriaMetrics", "age": 8}`
reader := strings.NewReader(data)
var b byte
for {
b, _ = reader.ReadByte()
if b == '8' {
b = '9'
}
fmt.Printf("%c", b)
}
}
// Output:
// {"name": "VictoriaMetrics", "age": 9}
On the other hand, we have RuneReader, which really shines when you’re working with text — especially Unicode.
When handling text what you care about are characters (or “runes” in Go) rather than individual bytes. Since Unicode characters can be anywhere from 1 to 4 bytes in size, using Read([]byte) would force you to manually decode those bytes into characters, which can be a hassle.
Let’s look at a quick example:
func main() {
// Create a reader with a string that includes some emoji
data := "Hello 🌍"
// First loop using ReadByte
bufReader := bufio.NewReader(strings.NewReader(data))
for {
part1, err := bufReader.ReadByte()
...
fmt.Printf("ReadByte: %q (byte value: %d)\n", part1, part1)
}
// Second loop using ReadRune
bufReader = bufio.NewReader(strings.NewReader(data))
for {
r, size, err := bufReader.ReadRune()
...
fmt.Printf("ReadRune: %c (size: %d bytes)\n", r, size)
}
}
// Output:
// ReadByte: 'H' (byte value: 72)
// ReadByte: 'e' (byte value: 101)
// ReadByte: 'l' (byte value: 108)
// ReadByte: 'l' (byte value: 108)
// ReadByte: 'o' (byte value: 111)
// ReadByte: ' ' (byte value: 32)
// ReadByte: 'ð' (byte value: 240)
// ReadByte: '\u009f' (byte value: 159)
// ReadByte: '\u008c' (byte value: 140)
// ReadByte: '\u008d' (byte value: 141)
// ReadRune: H (size: 1 bytes)
// ReadRune: e (size: 1 bytes)
// ReadRune: l (size: 1 bytes)
// ReadRune: l (size: 1 bytes)
// ReadRune: o (size: 1 bytes)
// ReadRune: (size: 1 bytes)
// ReadRune: 🌍 (size: 4 bytes)
We first use ReadByte() to read one byte at a time, which works great for the ASCII characters.
But when we get to the emoji 🌍, things get messy, because it’s made up of 4 bytes. ReadRune reads characters (or runes) properly, whether they’re one byte or multiple bytes.
These interfaces are implemented by most common types in the standard library, bufio.Reader/Writer, bytes.Buffer and usually they need to implement an internal buffer to avoid repeated call to the underlying resource.
Stay Connected
#
Hi, I’m Phuong Le, a software engineer at VictoriaMetrics. The writing style above focuses on clarity and simplicity, explaining concepts in a way that’s easy to understand, even if it’s not always perfectly aligned with academic precision.
If you spot anything that’s outdated or if you have questions, don’t hesitate to reach out. You can drop me a DM on X(@func25).
Related articles:
- Golang Series at VictoriaMetrics
- How Go Arrays Work and Get Tricky with For-Range
- Slices in Go: Grow Big or Go Home
- Go Maps Explained: How Key-Value Pairs Are Actually Stored
- Golang Defer: From Basic To Traps
- Vendoring, or go mod vendor: What is it?
Who We Are
#
If you want to monitor your services, track metrics, and see how everything performs, you might want to check out VictoriaMetrics. It’s a fast, open-source, and cost-saving way to keep an eye on your infrastructure.
And we’re Gophers, enthusiasts who love researching, experimenting, and sharing knowledge about Go and its ecosystem.
Leave a comment below or Contact Us if you have any questions!
comments powered by Disqus